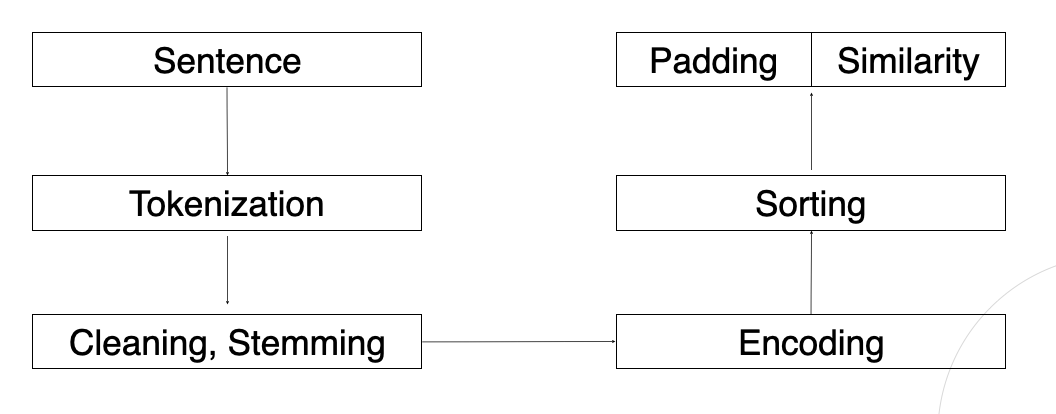
텍스트 전처리 과정 (3단계)
- 토큰화 : 문장을 단어 기준으로 자르는 과정 → I / love / you / for / always / Do / n’t / be / afraid
- 정제 및 추출 : 중요한 단어만 냅두고 불필요한 단어들은 다 자르는 과정 → I
waswondering if youcanhelpme on thisproblem - 인코딩 : 2단계에서 남겨진 단어들을 숫자로 바꾸는 과정 → [1,5], [1,3], [1,2,5], [1,0,0,0,0], [0,1,0,0,0]
언어의 형태소
문장 : 화분에 예쁜 꽃이 피었다
위 문장을 토큰화 진행 → 화분에 / 예쁜 / 꽃이 / 피었다.
BUT 화분"에" 가 아닌 "은","이"등등 될 수 있기 때문에 이와 같은 단어들은 조사나 어미도 토큰화에서 분리를 해줘야한다.
형태소 분석 : 화분 (명사) + 에 (조사) + 예쁘 (어간) + ㄴ (어미) + 꽃 (명사) + 이 (조사) + 피 (어간) + 었 (어미) + 다 (어미)
- 자립 형태소 : 명사, 수사, 부사, 감탄사
- 의존 형태소 : 조사, 어미, 어간
언어 전처리
컴퓨터 및 컴퓨터 언어에서 자연어를 효과적으로 처리할 수 있도록 “전처리” 과정을 거친다.
언어 전처리 과정
1. 토큰화 (Tokenization)
1) 주어진 문장에서 “의미 부여”가 가능한 단위를 찾는다.
- 띄어쓰기가 있으면 잘라주고 온점이 있으면 문장이 끝남을 알 수 있다.
예1) Machine / learning / methods / including / ANN / have / been / applied / in / compound / activity / prediction / for / a long / time.
2) 토큰화가 어려운 예시
예2) 어제 삼성 라이온즈가 기아 타이거즈를 5:3으로 꺾고 위닝 시리즈를 거두었습니다.
→ 구두점이나 특수문자를 전부 제거하는 작업만으로는 불가능하다.
3) 표준 토큰화: Treebank Tokenization (예2의 해결방법)
예3) Model-based reinforcement learning don’t need a value function for the policy.


TreebankWordTokenizer패키지 사용 (리스트 형태로 return을 해줌)
- 하이픈(-)을 하나의 단어로 인식해준다.
- n't(do not)을 다른 단어로 인식해준다.
4) 문장 토큰화: 문장 단위로 의미를 나누기
예4) My professor is looking for a student who is fluent on the Python programming. Yet, he also wants a person also capable of dealing with Pytorch.
- 문장이 매우 길 때 사용
5) 한국어 토큰화의 어려움
예5) 내 컴퓨터의 로컬 IP 주소를 192.168.0.5로 설정해 두었어. 혹시나 서버에서 접속이 필요하다면 기억해 두어야 해. 그 일이 끝나면 저녁 먹으러 가자.
- 이유 : "필요하다면"을 예로 들면, 아래와 같이 복잡하게 토큰화가 된다.
- 단어마다 모두 처리를 해줘야하기 때문에 아직 한국어 토큰화는 어렵고 패키지도 별로 없는 상태이다.

'인공지능' 카테고리의 다른 글
| [인공지능/Deep Learning] 딥러닝의 기초 - 활성화 함수 (0) | 2024.11.22 |
|---|---|
| [인공지능/Deep Learning] 딥러닝의 기초 - 퍼셉트론 (0) | 2024.11.21 |
| [인공지능/Deep Learning] 개념 정리 (0) | 2024.11.21 |
| [자연어처리 입문] - 언어 전처리 과정 (2) 정제 및 추출 (0) | 2024.11.19 |
| [자연어처리 입문] - 자연어 처리 소개 (0) | 2024.11.19 |